
When Practical Linux Forensics by Bruce Nikkel was released, I was excited to dig in to yet another DFIR book. While I am a casual user of Ubuntu and Arch distributions, performing forensic analysis on a Linux operating system doesn’t come up very often.
Practical Linux Forensics is well organized. Progressing through each chapter, I did not feel lost and was able to build on the information I comprehended from the previous chapter. Nikkel found an appropriate balance of detail and depth presented for the scope of this book – analysis of dead box Linux operating systems.
After studying Practical Linux Forensics, and testing various topics referenced, I am more familiar of the investigative value of the various artifacts presented throughout – from filesystems to pattern of life activity. Undoubtedly, I am now more informed on performing dead box forensic analysis of a Linux OS.
The book, marked up and tabbed, is always available to reference the valuable information it contains. What better way to reinforce what I learned than to work through a couple of Magnet User Summit capture the flag images from Cyber5W‘s Mini Linux Forensics challenge?

I completed the challenge earlier this year, but I feel I have a better grasp of several Linux concepts after reading Practical Linux Forensics. The challenge appears to have ended, but the premise of the scenario involves two Linux images of an employee’s computer. The employee is suspected of violating company policies that include browsing illegal websites, downloading illegal images, and illegal music files. Joshua James (DFIRScience) has a great video walk-through and blog.
When the challenge was active, I used the SANS SIFT workstation. Using a Linux system for forensic analysis makes absolute sense, but that’s been done already. For this exercise, I used X-Ways Forensics (v20.6) and Windows Subsystem for Linux (WSL2). I also noted where in the book I was able to reference to answer a question.
Creating a New Case and Verifying the Image
I started with a new case in XWF, File | Create New Case. Then added both images to the case, File | Add Image…

With both images added, the description embedded in the E01 files may be reviewed. The hash can be verified by selecting the evidence item then, [right-click on evidence item] | Properties… | Verify hash.
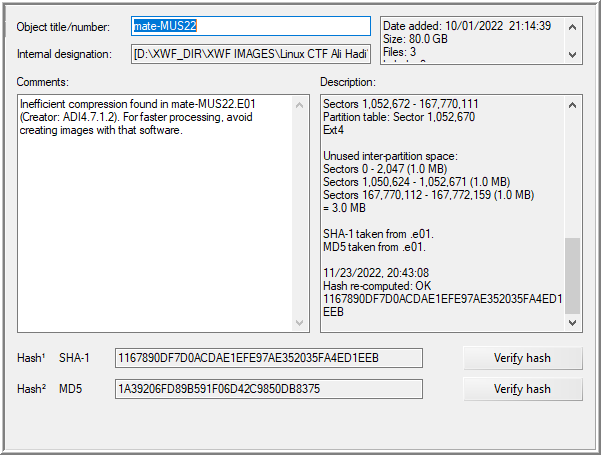
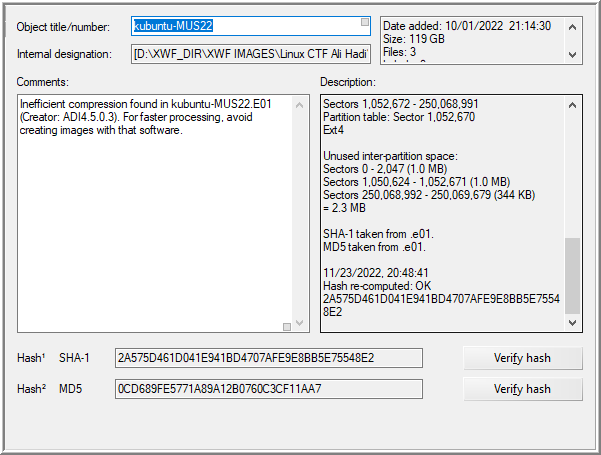
Mate
Question 1: What is the ID of the last boot?
In Chapter 5, Nikkel identifies the locations of several logs found on a Linux system, including the system.journal that contains the boot-id which is used as an identifier of periods from start up to shutdown (25).
To view the contents of the log, journalctl is needed to query its contents. XWF doesn’t support .journal files, but Nikkel states “you can copy and analyze the journal files on a separate Linux analysis machine using the journalctl command” (pg. 125).
The location of the local .journal files is /var/log/journal/8022936e63e14aa6877a1a9d82460409. The long string of numbers following “…/journal/” is the machine-id. Since the question is asking for the last boot, I targeted the file in-use, system.journal, which contains logs generated by system service and the kernel (123-124). To copy this file out, I used Recover/Copy… and choose not “Recreate original path”. If I wanted to determine previous boot-ids, I may Recover/Copy… the entire directory.
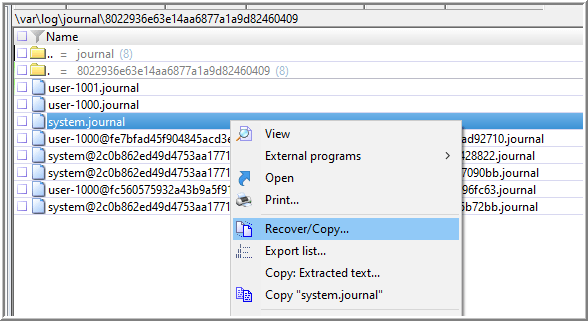
With the copy of the system.journal file copied to the local system, I can start WSL and run the journalctl command using the flags for a file or directory.
journalctl --file system.journal --list-boots
OR
journalctl --directory 8022936e63e14aa6877a1a9d82460409/ --list-boots


Question 2: How did the user install Google chrome, date, time?
What I especially appreciate about Practical Linux Forensics is the depth it goes into various distributions. Each distribution does things a little bit different – including the method of installing applications. To begin to answer this question, I must understand the distribution I’m working with by reviewing the release information of the image in /etc/os-release (185). Just as Nikkel stated, this was a symlink to /user/lib/os-release.

In Chapter 7, Nikkel describes the various package management systems for multiple distributions. Considering Ubuntu is a Debian-based system and uses apt, we can review /var/log/apt/history.log to determine the start/end times of apt commands (205). After traversing to that log, I ran a search in File mode for “chrome” to find the command for “apt install -y google-chrome-stable”, which confirms Chrome was installed using apt.
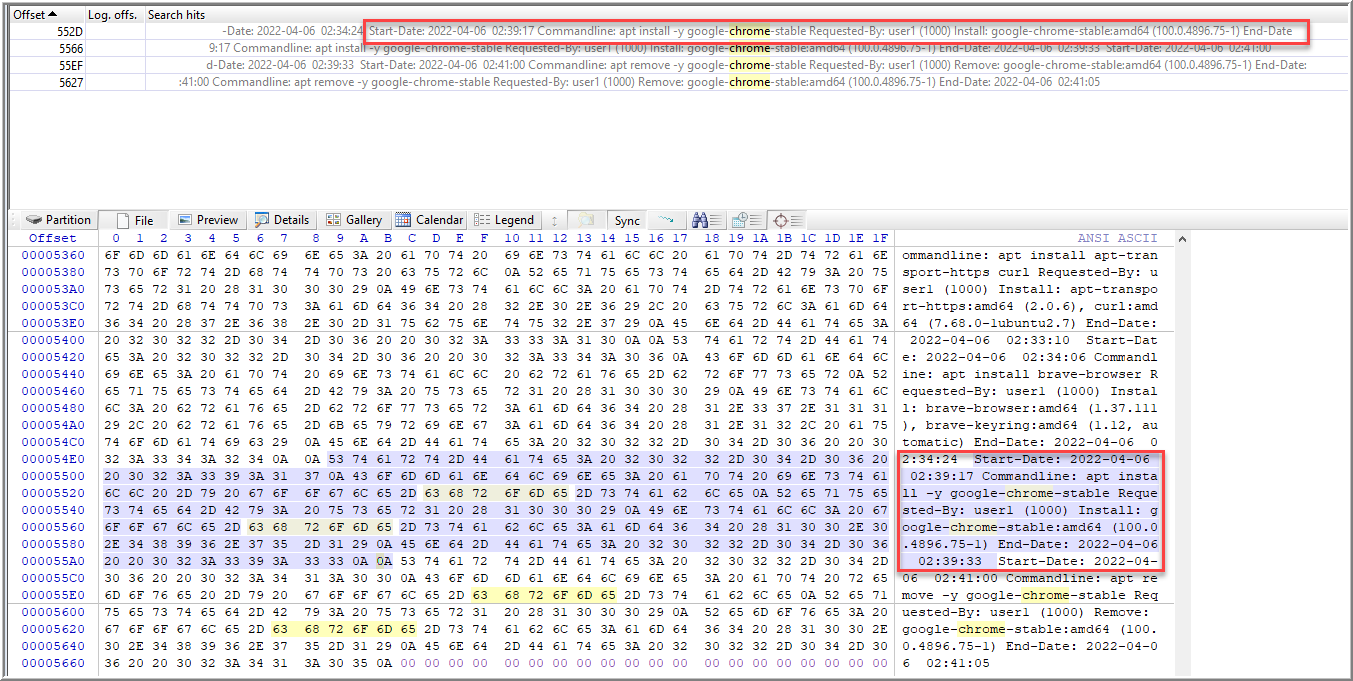
Question 3: What date and time did the user install it [chrome]?
In the same log file, that entry includes the “Start-Date”, 2022-04-06 02:39:17.
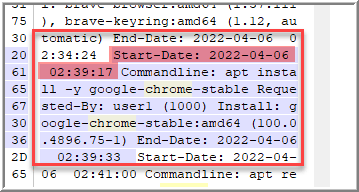
Question 4: The name of a repository from which more than one extra application was installed from?
Of all the questions, I found this one the most difficult for me to conceptualize. How are repositories involved with extra applications? From my perspective – when I upgrade or install software, I just use the pacman or apt commands, and the rest is magic.
Wrapping up Chapter 7, I begin to understand that repositories are involved with software and installation – they are simply locations where they’re stored and retrieved from. On page 202, Nikkel describes packages, which contain all the necessary information to install and remove software from the system, and are downloaded from these repositories. Then there are files, sources.list and sources.list.d/*, that “define the configured external repositories for a particular Debian release.” Nikkel further explains that repositories explicitly added are saved to a file in sources.list.d/ directory (205).
Following that primer, I understood that I should look for the name of a repository that was used to install multiple, non-standard, applications. Based on Nikkel’s explanation, I started with sources.list.d directory first.
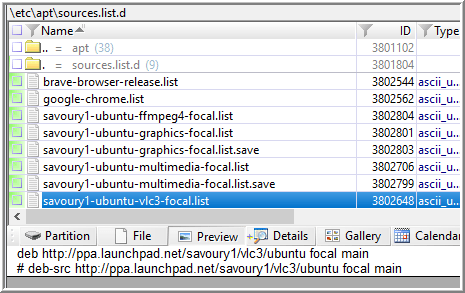
I recognized vlc3 and realized that may be a non-standard application among the other similar looking *.list files. Reviewing the contents of that file, I see a URL for ppa.launchpad.net.
Launchpad is a software collaboration site and PPAs are Personal Package Archives. Developers build Ubuntu packages and make them available to other Ubuntu users. Savoury1 is the name handle for Rob Savoury who manages the PPA at https://launchpad.net/~savoury1. In Savoury’s overview, he names his PPA, “ppa:savoury1”.
I can use that to search files in the image to see if it hits anything using Simultaneous Search. I select the option to only search the primary partition.
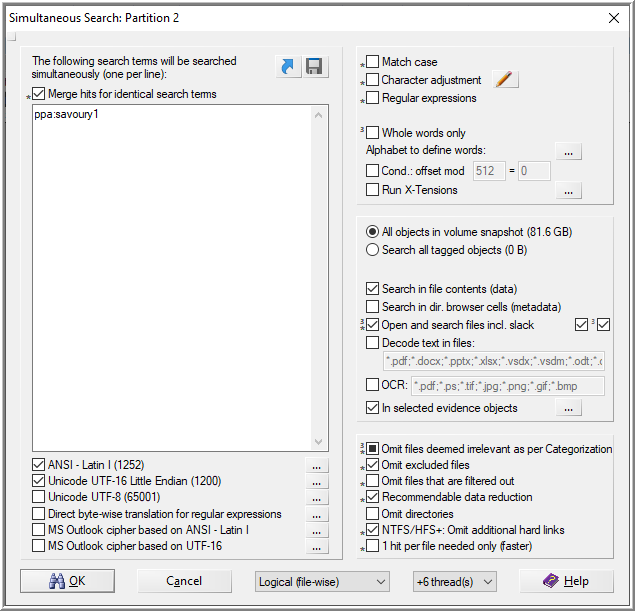
An interesting hit is the file, .bash_history.
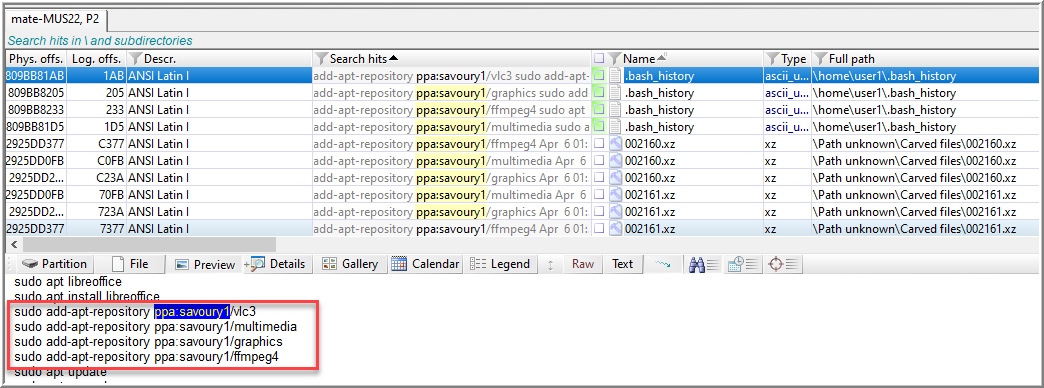
After running the command, man add-apt-repository, in WSL, I learned vlc3, multimedia, graphics and ffmpeg4 are non-standard applications from ppa:savoury1 and were added using the command, add-apt-repository.
Question 5: What is the name of the desktop session?
Nikkel describes sessions as the “duration of a user login” (275); however, that didn’t explicitly provide me any direction. If I search “session” in Nikkel’s electronic version of the book that came with the physical copy, I found myself on page 358 looking at the path, “var/lib/AccountsService/users/*“, that provides a user’s default or last session login settings. Cool.
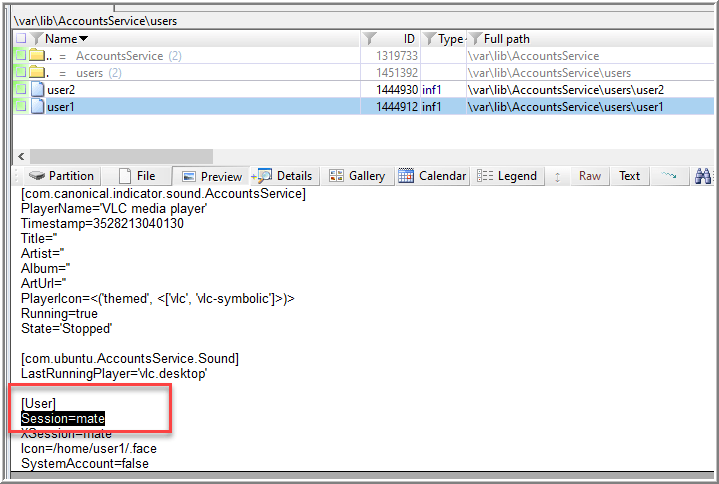
After additional searching, I also found a session configuration file exists at /usr/share/xsessions that will also answer this question.

Question 6: What was the name of the suspicious domain the user visited?
Chapter 4 was very interesting to me. It describes how files and directories are organized and their purpose. Nikkel includes a description of the user home directory, which all users on a Linux system have and “contains significant amounts of potential evidence investigators can use” (88). Taking a quick look at user1’s directory, I get a get clue that Firefox is an installed application.
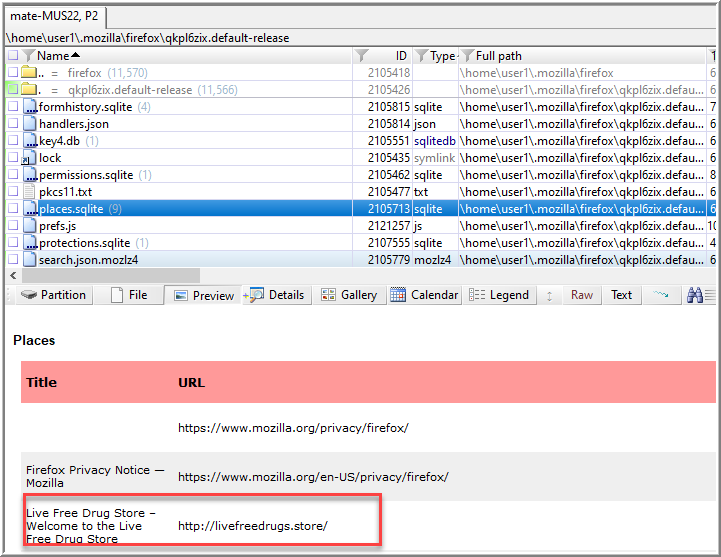
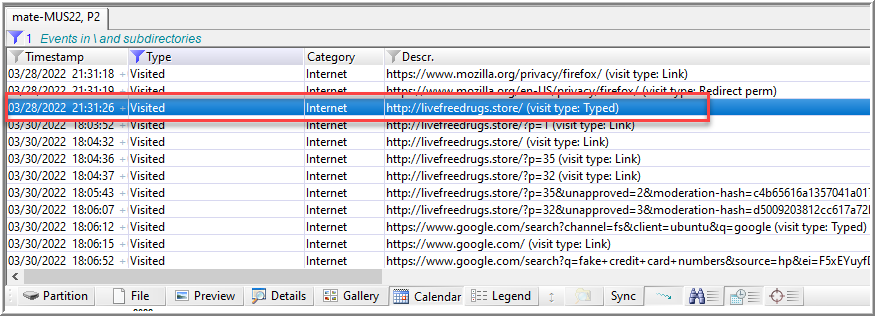
Browsing through the .mozilla directory, I found places.sqlite at /home/user1.mozilla/firefox/qkpl6zix.default-release/. I previously wrote about using XWF to review and report on internet browser activity. That same approach is applicable here, which yielded a displayable HTML report and .tsv files of the various tables XWF added as child objects/virtual file. Reviewing those files reveals a particularly suspicious domain.
Kubuntu
Question 1: How did the user install Google chrome, date, time?
This appeared to be a similar question from the Mate image, so here I thought I would strike gold from the same log.
I previously found that the user file, .bash_history, was extremely helpful. In Chapter 10, Nikkel goes in depth on reconstructing user desktop and login activity – including shell history that is recorded in that file. After a text search for “chrome” of that file, a command for dpkg was found (281).
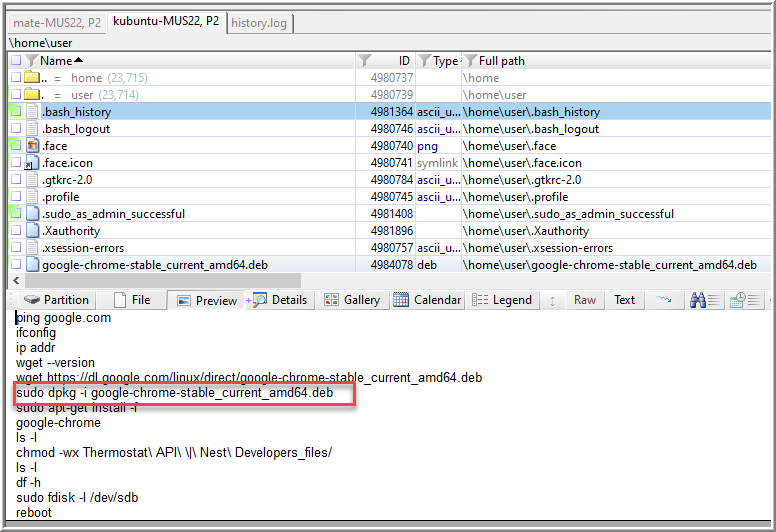
On page 204, the command dpkg “manages the installation, removal, and querying of packages.” I also learned I can check out a package’s current state in /var/lib/dpkg/status.
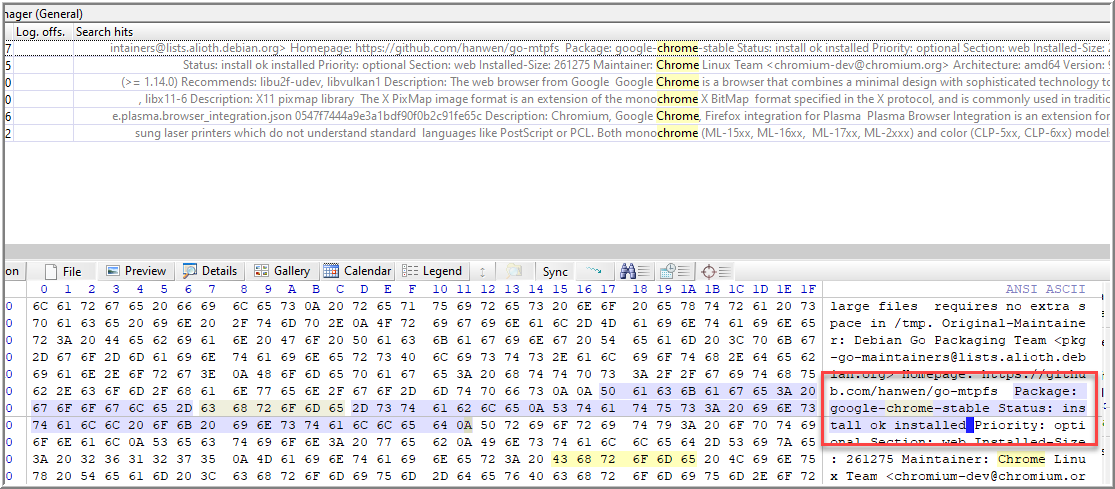
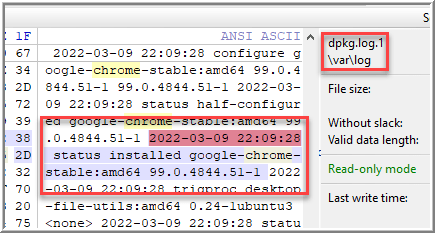
While I was able to confirm that Chrome is installed using dpkg, I didn’t have a date or time. For date and time information, /var/log/dpkg.log file may be viewed, which does include timestamp information for the installation, removal, upgrade, etc, of a package (205). Reviewing the current log didn’t return any results, but these log roll over. Searching dpkg.log.1 revealed the timestamp of interest.
Question 2: How did the device go to sleep?
In Chapter 6, Nikkel covers forensic analysis of the Linux system boot and initialization process. Starting on page 175, Nikkel describes how to analyze power management activities – including sleep. There’s also the Advanced Configuration and Power Interface (ACPI) that controls various power management systems and components, whose messages may be logged to systemd (17, 176).
Since I already had a local copy of the .journal files, I grepped for the keyword, “sleep” and returned two lines before and after.
journalctl --directory 297761177be5448689630a6b48a5fed8/ | grep -B2 -A2 sleep
After scrolling through the results, I noted systemd managed the suspension process followed by a human proximity indicator, lid closure (179).

Question 3: How many privileged commands did the user run?

In Chapter 10, Nikkel reviews how to analyze elevated privileges that are recorded by the systemd log (294). Here, I grepped for the keyword “sudo” in the .journal files.
journalctl --directory 297761177be5448689630a6b48a5fed8/ | grep sudo
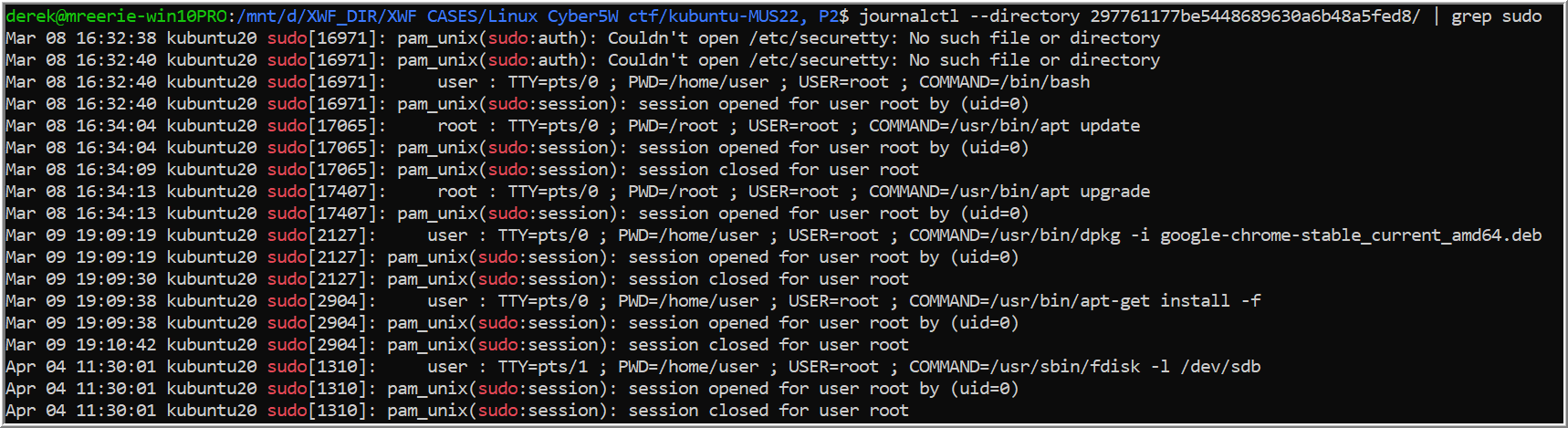
This returned records where a sudo command was used or a process using sudo. Several lines include: Process name, process id, the user, which pseudo terminal was used, the printed working directory where the command was ran from, the command running as root, and the command itself. I initially counted by hand, but I was enlightened by James’ and Heller’s use of the wc command against the /var/log/auth.log* file.
But here’s a wonky command that I did here.

Question 4: What application was used to open the Top devices file?
I didn’t know what a “Top devices” file was, but I was able to filter for the file name after I explored the partition recursively.
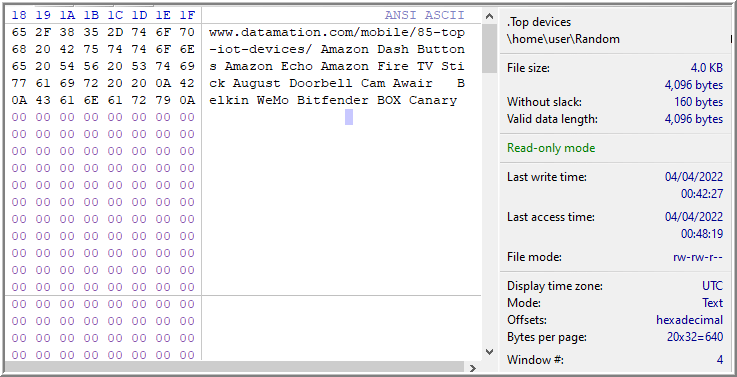
Nikkel briefly discusses recent files in Chapter 10 that primarily reference files under .local/share/. It contains files that use the .xbel extension, which refers to the XML Bookmark Exchange Language (310). I wasn’t able to immediately identify any hint of the file “Top devices”, so I ran a Simultaneous Search for the keyword “top devices” against the files within .local/share/.
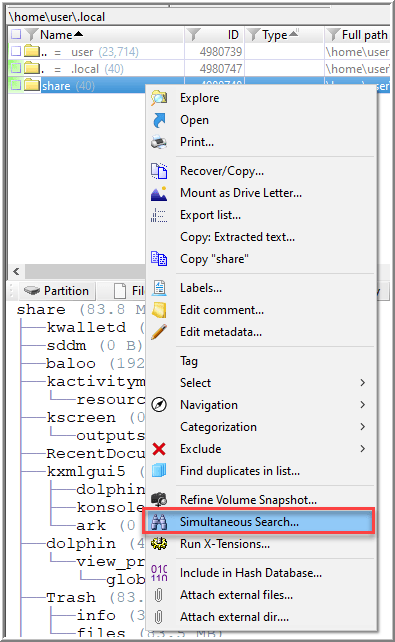
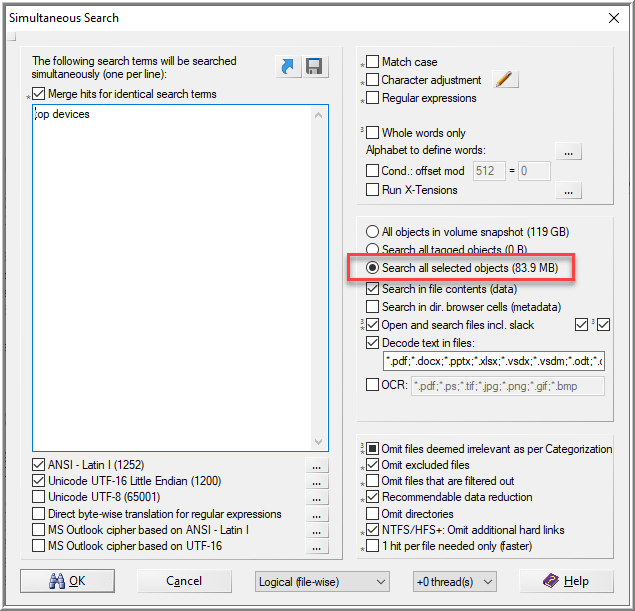
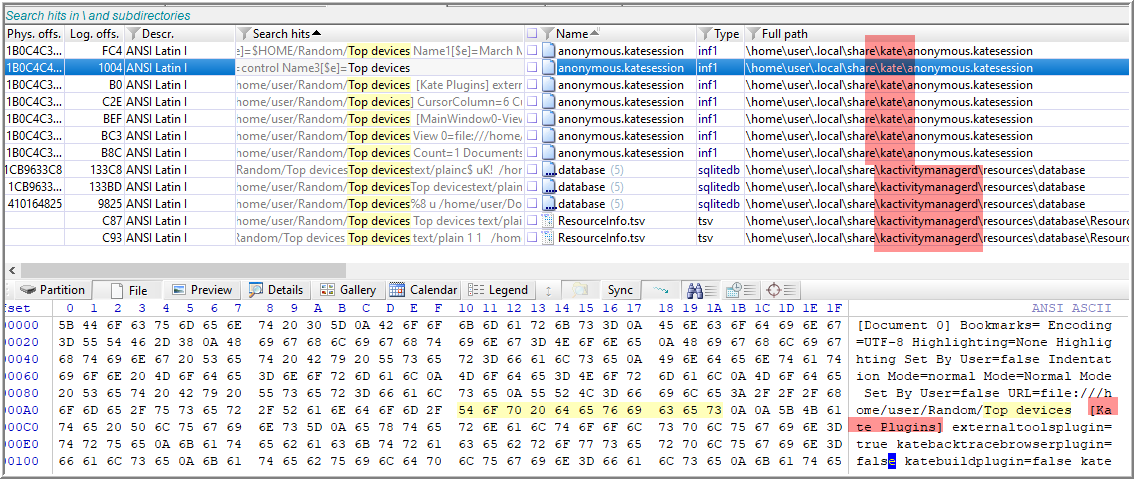
Reviewing the results, files returned are “kate” and “kactivitymanagerd”. Kactivitymanagerd is a component of the desktop environment, KDE, and records the activities of a user in a SQLite database. Interesting note: This appears to be the Linux version of Windows Timeline.
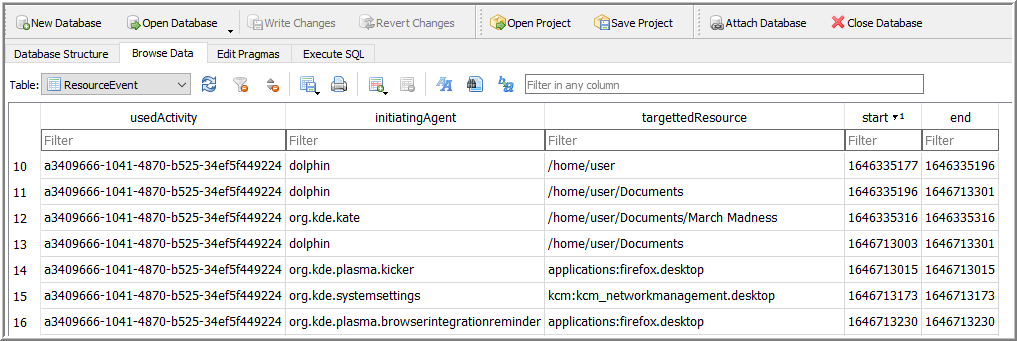
Kate is a KDE text editor and is the application of interest. It’s also an example how individual applications implement their own method of storing bookmarks and recent documents (331).
Question 5: What was the UUID of the main root volume?
Chapter 11 is all about attached peripheral devices. Close to the end, Nikkel describes how to find evidence of mounted storage by reviewing the file, fstab, with / as the root filesystem with the installed operating system (336). From personal experience, knowing about the UUID in the fstab file was helpful to set up a software MD RAID for testing.
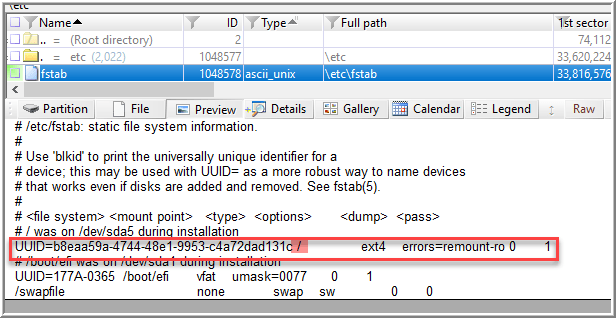
For good measure, I also used the journalctl command in WSL to grep events containing “uuid”.

Summary
Practical Linux Forensics was a worthwhile study for me. I imagine others will arrive to the same conclusion. It was nominated Forensic 4:cast DFIR Book this year for 2021, after all. As a way to a reinforce my understanding of the material, I worked through Cyber5W’s mini Linux challenge that was offered earlier this year. What I found particularly valuable is exploring the combination of XWF’s searching capabilities, and the flexibility of WSL for critical commands without needing to boot to a Linux virtual machine.
While the challenge is not active, Dr. Ali Hadi generously donated more of his time to upload the two images for Mate and Kubuntu, here. There’s another image for Ubuntu, as well!
Recommendations:
- Buy and read Practical Linux Forensics by Bruce Nikkel.
- Practice with Cyber5W’s Linux images.
- Take notes, validate, and document the time spent.

Leave a comment