X-Ways Forensics v20.3 was released with Optical Character Recognition (OCR), using Tesseract, capability beginning on 07/20/2021.
Guidance on using OCR is documented in section 5.20 of the manual. The downloadable Tesseract package from X-Ways includes several languages with tessdata_fast .traineddata files. These files are described by the Tesseract project team as “a speed/accuracy compromise as to what offered the best ‘value for money’ in speed vs accuracy.”
tessdata_best is also available and described as the “best trained models.” The XWF manual notes these models will take additional time to process.
The .traineddata files in use are located in XWF’s program directory at:
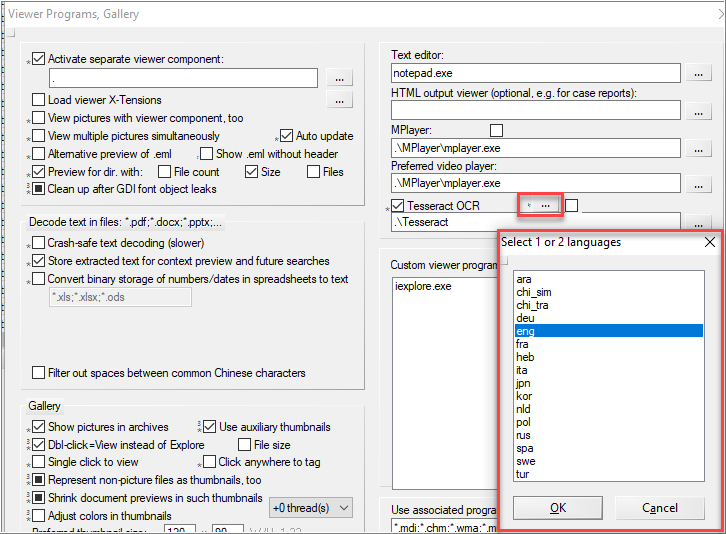
[...]\xwf20.5\Tesseract\tessdataFrom Options | Viewer Programs, up to two languages may be selected. X-Ways advises to not select Chinese/Japanese and Latin letters at the same time noting that it will “deteriorate the recognition of the Asian characters.”
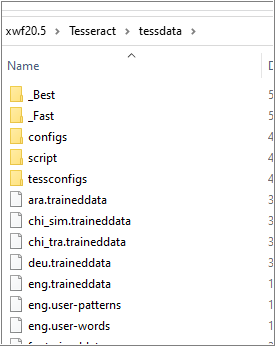
When I experimented with the models, I added two directories: _Best and _Fast. These directories are for models not in use. If I wanted to switch from a fast English model to a best English model, I would:
- Move eng.traineddata from tessdata to _Fast.
- Move eng.traineddata from _Best to the tessdata.
Based on limited observations, the difference between the English models, aside time to process, appear to be minor.
XWF Video Image Capture + OCR Workflow
An interesting way to use the OCR function is to apply it to still images captured from video. DFIRScience did just that with video2ocr Tsurugi. If you have XWF handy, this workflow might be of interest.
Setup
I started with a screen captured video wherein I copied and pasted two lines and six sets of text (presented from left to right) in English and Japanese over 60 seconds to a text editor. The text used are lyrics from a classic 1980’s song. On scale of A-F, I C’d my way through three years of Japanese in high school and haven’t used it since; therefore, I relied on the Internet for a translation. I saved the screen captured video I created as an .mp4, then added it to an existing XWF case.

Display resolution is 3440×1440. It was also recorded with a white background and zoomed in at 170% – this was primarily a workflow exercise and not intended as validation/accuracy of XWF’s OCR capability.
Consistent with X-Ways’ recommendation, I expressly selected Japanese (fast model) in Options | Viewer Programs.

Capturing Stills from Video
1. With a video file added to the case, right-click on the video file to select the Directory Browser’s context menu | Refine Volume Snapshot…
2. Check the boxes, Verify file types with signatures and algorithms AND Capture sporadic still images from videos. The list of extensions already includes *.mp4.

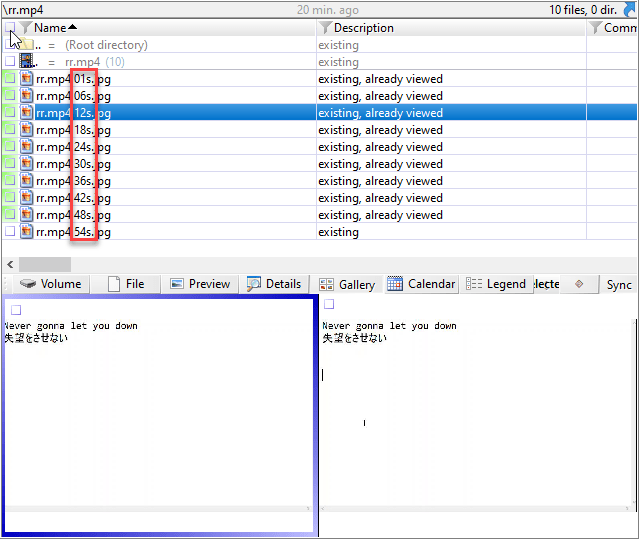
3. Clicking on […] will show more options to set the interval or number of stills to be captured. I opted for a fixed number (10) of stills to capture.

4. XWF captured 10 images from the 60 second video and were added as child objects. Note that each capture is appended with the number of seconds where it was captured from the video.
Activating OCR
Below are three OCR activation methods using XWF v20.5 SR-2:
- Activating OCR on a single eligible file using the Preview sub-mode button, Text/OCR.
- Via Directory Browser’s context menu | Copy: Extracted text…
- Simultaneous Search
Sub-Mode
1. View the captured still in Preview mode.


2. Click on the sub-mode button, Text, to activate OCR.

Extract Text
1. Optionally, you may also extract the OCR’d text (Directory Browser’s context menu | Copy: Extracted text… ). This was introduced on 11/16/2021 with 20.4 Beta 7 before its official release on 11/23/2021.
| Checkbox | Description |
| OCR | Activates the OCR capability to extract text. |
| Process ONLY files that require OCR | Action will ignore all other files, i.e., .txt and .doc, to process only pictures and certain PDFs. |
| Store extracted text for context preview and future searches | Saves the decoded text in the Volume Snapshot. Applies to text extraction of documents and images, if enabled. |
| Comments | OCR’d or extracted text is added as a comment and viewable in the Comments column. |
| Prefix | [OCR] or [Extracted Text] will precede the text in the Comments column, if Comments is checked. |
| Child objects (.txt) | Extract texts and adds “OCR.txt” or “Extracted Text.txt” to the file as a child object. |
| File (.txt) | Extract the OCR’d or decoded text to a text file. |
| Clipboard | Copies the OCR’d or extracted text to the clipboard. |


2. If several Comment rows of interest were identified, selected rows may exported via the Directory Browser’s context menu | Export List…


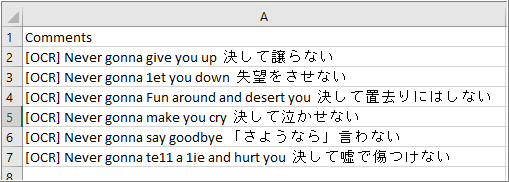
3. Text may also be extracted from multiple items to the Clipboard, which then may be pasted to a text editor.

Simultaneous Search
1. While there may be use cases to extract OCR text, I imagine the most practical utility of OCR is with simultaneous search.

2. Results may be viewed by using the Search Hit List button.

3. With a reduced sample of files that matched the search terms, those select files and OCR’d text may then be extracted to the Clipboard.
Future Improvements
A second preview of v20.6 was recently announced. The preview includes a 3-state checkbox to apply Exif orientation in metadata in Preview mode. I look forward to exploring that additional flexibility.
v20.6 preview 2 also made improvements to text extraction of which will also be included in future releases of v20.4 and v20.5!
Summary
XWF is OCR capable since November 2021. XWF’s Tesseract package is bundled with multiple language models optimized for a balance between speed and accuracy. If a use case requires it, Best models may be easily experimented with.
While XWF is capable of recognizing up to two languages, recognition quality of Chinese/Japanese may be reduced if selected with a Latin language.
XWF’s function to capture stills from video may be combined with OCR to potentially extract additional text that would not have otherwise been available. After the stills are captured, OCR may be activated by using the Preview’s sub-mode button, Text/OCR, on a single file, from the directory browser’s context menu via Copy: Extracted text…, and Simultaneous Search.
As XWF continues to update and improve, it’s always a good idea to read those public announcements as they’re released.

Leave a comment